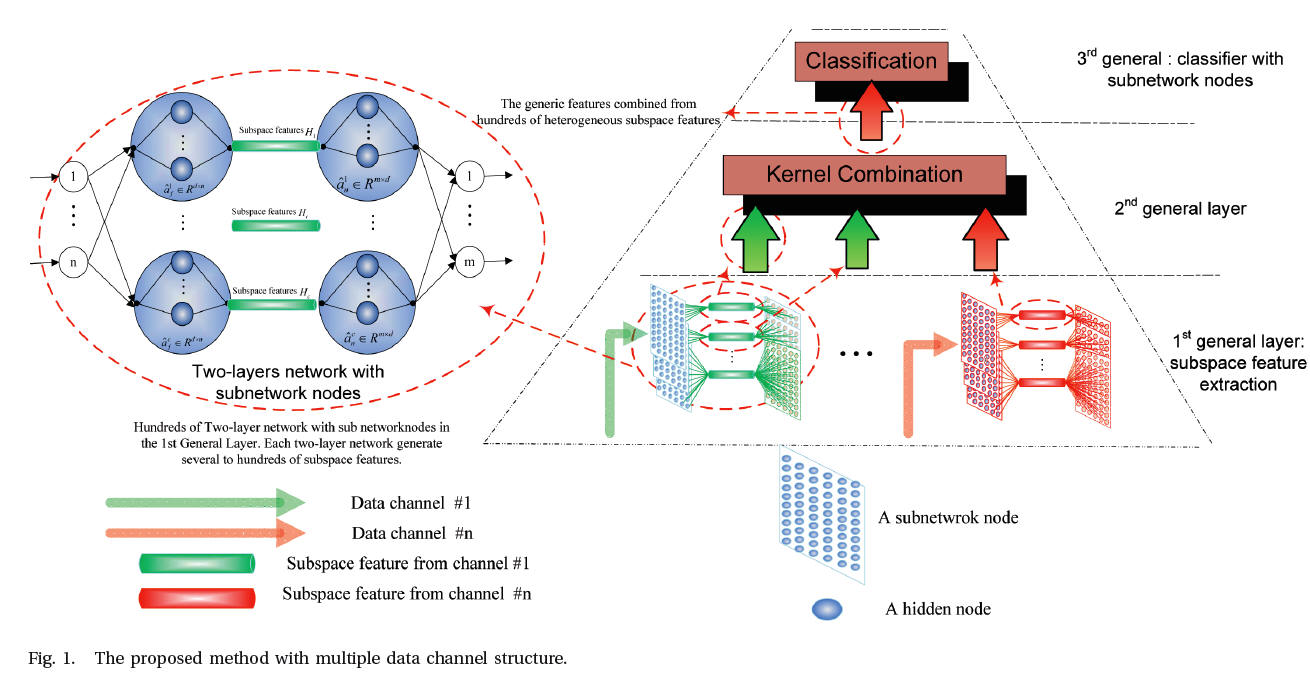
Features combined from hundreds of mid-layers:
Hierarchical networks with subnetwork nodes
Yimin Yang and Q.M. Jonathan Wu
Abstract: Most actual images, such as those of human faces, industrial images, and MRI images, are high-dimensional data. Feature representation is mainly for purposes of extracting useful information and using this information to build non-supervised classifiers, supervised classifiers, and/or other types of predictors. At present, accumulated direct biological evidence supports the theory that neuron activity in the mammal prefrontal cortex is highly heterogeneous, partially random, and disordered. Inspired by these theories, we believe that combined features extracted from mixed selectivity neurons may be central to complex behavior and cognition. In this paper, we find that the learning behaviors of features combined from hundreds of mid-layers are very similar to the above-mentioned biological evidence with respect to their intrinsic operation mechanisms. Using these similarity relationships, we can greatly improve the practical application performance of feature representation. The novelties of this work are as follows. First, a subnetwork node, which itself can be formed by several hidden nodes, has various capabilities, including feature learning, dimension reduction, and so on. The subnetwork, like neural representations in the mammal cortex, can be functional as a local features extractor. The top layer of a hierarchical network, like the mammal cortex in the brain, needs such subspace features produced by the subnetwork neurons to get rid of factors that are not relevant, but at the same time, to recast the subspace features into a mapping space so that the hierarchical network can be processed to generate more reliable cognition. Experimental results show that this subnetwork structure boosts the generalization performance of the final classifier dramatically. Second, unlike the common understanding that the higher the dimensional space enhancing the richness of the representation to which the feature is mapped, the better the generalization performance of the classifier, this paper shows that the number of channel-data play a significant role in generalization performance improvements and not in feature dimensionality. Hence compared with the high-dimensional features, low-dimensional features with the proposed method could provide a comparable or even better performance, which dramatically boosts the learning speed. Third, similar to biological learning, our hierarchical structure could use any type of features without pre-conditions and provide a parallel and unified learning model for data fusion, classification, and dimension reduction. Our experimental results show that our platform can provide a much better generalization performance than 50 other rival methods hundred times faster speed. For instance, the learning platform without any pre-trained big data achieves categorization accuracy of 98.2% on the Scene15 dataset in 20 seconds, which is even higher than human-level performance.
――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――
Learning Structure:
__________________________________________________________________________________________________________________________________________________________________________________________________________________
____________________________________________________________________________________________________________________________________________________________________________________________________________________
Downloads
1) Scene-15
2) Caltech101